はじめに
みんな大好きAuto Recovery。
設定するのはいいが、それが実際に動くところを見てみたい。どうしたらできるか。
結果から言うと「ユーザー起因での検証は不可」なのですが、そこに至るまでの経緯と、AutoRecoveryとは何ぞやを以下の2部構成で記します。
1.過去に試した元ネタをベースに再編集したもの
2.上記を基に、追記・補足した内容
1.元ネタベース
過去に別の場所で投稿したものを再編集したものです。
AutoRecoveryの機能テストは実施できるか
2016年の記事なので、現在と状況が異なる部分もあります。情報が古いことを嘆くのではなく、むしろ当時と比較してバージョンアップした部分などに思いを馳せましょう。本質的な部分は変わりありません。
プロローグ
EC2インスタンスに(主にAWS側の)問題が生じた時に、自動で復旧を行ってくれるAutoRecovery。
みんな大好きなので、とりあえず設定しておきますよね。
単体テストの時に、試験項目に入れるか入れないか悩んだりしますよね。しませんか。
(テストには入れなくていいです。)
ともかくぜひ実際に動くところを見てみたいと思い、テストをする方法はないかを調べてみました。
ない
ないようでした。
軽くネットで調べてみるだけでも、「無理」感がひしひしと伝わってきます。
とはいえ実際に手を動かさないのもダメかと思い、無理やり考えつく方法を試してみました。
Cloudwatchアラームの設定をいじる
AutoRecoveryは、CloudWatchの”StatusCheckFailed_System”メトリックスに紐づくアクションとして設定します。正常稼働時にはそのメトリクスで検出される値は「0」なので、アクションのトリガーとなるしきい値を、例えば「< 1(1より小さくなったら)」のように設定すれば、アラームの状態を「警告」に遷移させることは容易です。
その状態で、「アラームが次の時:警告」「次のアクションを実行:インスタンスの復元」に設定すれば、実際にAuto Recoveryが発動するような物理ホストの障害が起きなくとも、アクションを実行させることはできます。
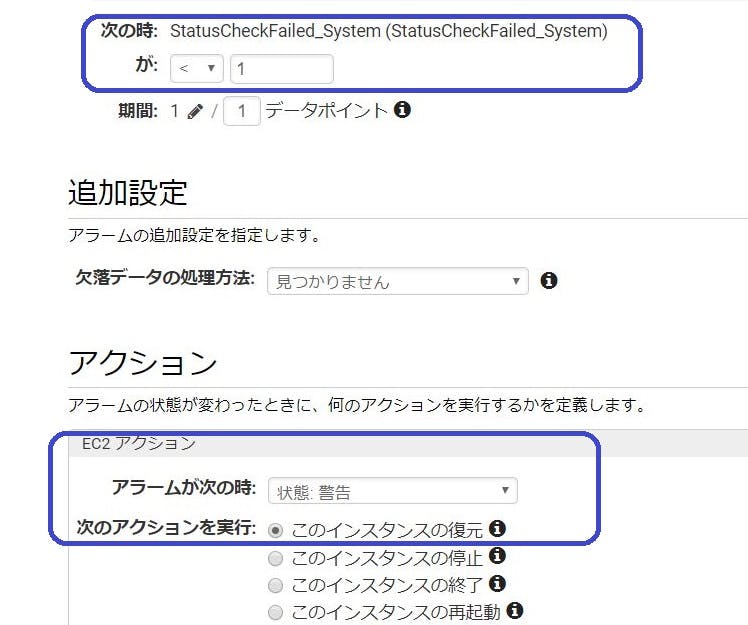
さっそく試してみます。(ちなみに画像は2019年に撮りなおしたもの。)
律儀に送ってくれるメール
実際に試してみたところ、「警告ステータスに遷移した」「紐づくアクションが実行された」という履歴はCloudwatchアラームの画面から確認できますが、実際に動くところは見れません。そしてAWSのrootアカウントに以下のようなメールが届きます。
件名:[Auto Recovery] Amazon EC2 instance recovery: No action taken
Dear Amazon EC2 Customer,
An Auto Recovery action was triggered for your EC2 instance ID: i-xxxxxxx in the ap-northeast-1 region, but no action was taken.
EC2 Auto Recovery re-verifies the system health status of an instance before proceeding. During this verification step your instance reported healthy and Auto Recovery was therefore not initiated.
Common reasons for this include:
1. A system health check failure was very short-lived and recovered by the time Auto Recovery was initiated
2. A user performed a manual override of the CloudWatch alarm by setting the alarm state to ALARM
If you have any questions or concerns, you can contact the AWS Support Team on the community forums and via AWS Premium Support at: http://aws.amazon.com/support
Sincerely,
Amazon Web Services
This message was produced and distributed by Amazon Web Services, Inc., 410 Terry Avenue North, Seattle, Washington 98109-5210
僕の乏しい英語力によると、以下のようなことが書かれているようです。
「インスタンスのシステムステータスはヘルシーなようなので、何のアクションも起こしませんでした。」
「考えられる主な理由としては、1.短時間でヘルシーになったか、」
「2.ユーザーが手動でアラーム状態に遷移させたから。」
ばれてました。
ということで、AWSとしてはCloudWatchアラームのアクションが実行された後に、物理ホストの状態なども踏まえて、復旧アクションを行うかどうか判断しているようです。そうなるとやはり小手先のやりくりでは動作確認のテストは無理そうで、実際にAWS側の物理的な問題が生じるのを期待するしかないようですね。(実際にAutoRecoveryが発動しても恐らく透過的であり、ユーザーから確認できるかは疑問ですが)※1
おまけ:statistic[Minimum] が唯一サポートされている、とは?
アラームの設定についてドキュメントを参照する中で、気になる記述を見つけました。
メトリックス”StatusCheckFailed_System”について「統計」では「最小」を選択するよう記述してあり、それについて下記のように書かれています。※2
Note
これは現在サポートされている唯一の統計情報です。
サポートされているとは何を指すのか?
サポートされていないstatisticを選択するとどうなるのか?
ということがわからなかったので、サポートに問い合わせてみました。
回答:ユーザーの意図しない結果を避けるため
例えば「統計」で「最大」を選択していると、設定変更や障害などで一時的にメトリックスが上がった場合でも、アラームが生成されることになる。そういったユーザーが意図していない結果を避けるために、ドキュメントには「サポートされ」た統計情報だと記載しているとのことでした。
感覚的には「推奨」といったレベルでしょうか。なるほど。
(第一部完)
2.追記、補足
当時の状況が分かったところで、適宜情報を補っていきます。
ちなみに上記のメールは、今でも同じことを試すと送られてくるので、自由に触れる環境でない場合は気を付けてください。(私はこれを新人の頃にお客さんの環境でやって、こんなメール届いたんだけど何?と言われたことがあります。)
(不発に終わった時だけでなく成功時にもrootアカウント宛に送ってくれるそうです。物理ホストの空き不足やインスタンスストアを使用していて復旧アクションがこけた時にもメール通知は行われます。)
AWS アカウントルートユーザーは、SNS トピックが指定されていない場合でも、自動インスタンス復旧アクションが発生すると、常に E メール通知を受信します。
Amazon CloudWatch アラームへの復旧アクションの追加
2.1.改めてAuto Recoveryとは
以下のページに一通り必要な情報がまとまっています。
[インスタンスの復旧]
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-instance-recover.html
- Cloudwatchアラームのアクションとして設定する
- StatusCheckFailed_Systemメトリクスがアラーム状態になった際に発動する
- 主な原因は以下の通り
- ネットワーク接続の喪失
- システム電源の喪失
- 物理ホストのソフトウェアの問題
- ネットワーク到達可能性に影響する、物理ホスト上のハードウェアの問題
- 主な原因は以下の通り
- 発動すると、EC2インスタンスを新たな物理ホストにマイグレーションさせる
- マイグレーション後も以下の情報を引き継ぐ
- インスタンスID
- プライベートIPアドレス
- パブリックIPアドレス
- Elastic IPアドレス
- メタデータ
- マイグレーション後も以下の情報を引き継ぐ
- 設定するためにはいくつか条件がある
- インスタンスタイプが特定のものであること
- テナント属性が「専有ホスト(Dedicated Hosts)」でないこと
- インスタンスストアを利用していないこと
- インスタンスストアは物理ホストに紐づくからね…
たまに「Auto Recovery仕掛けておけば何かあっても自動で直してくれるんでしょ?」と聞かれますが、物理ホストより上の領域で障害があった場合には対応してくれないので、「あなたの思い浮かべてる”何かあった時”と”直してくれる”は具体的に何を指しているんですか?それによって回答が変わります」をマイルドにした表現で聞いておきましょう。
2.2.AutoRecoveryによる物理ホストの移動はライブマイグレーションなのか
ここでのライブマイグレーションとは、仮想マシン上のOSの停止を伴わずに、異なる物理ホストへ移動することを指しています。結論から言うと、「違う」と考えています。
少し寄り道して、先述の※1にて、「ユーザから見て透過的である」という記述があります。急に当時の自分にしては知ったような口ぶりが出てきたので、どこで聞きかじった言葉だと思い、調べてみました。恐らくこちらの記事を参考にしたのだと思います。
[EC2 Auto RecoveryはどのくらいAuto Recoveryなのか]
https://yoshidashingo.hatenablog.com/entry/2015/01/15/140446
上記の記事においては、「ホストの入替えはユーザーから見ると透過的である」と記載があります。確かに物理ホストの入れ替えが起こったことは、マネジメントコンソールに表示されるわけではないので、確認しようがないかと思います。ただ、過去の自分の記事にあるような「Auto Recoveryが起こったこと自体が透過的で、ユーザーが気づけるか分からない」ということは無いはずです。
Auto Recoveryは再起動を伴う
上述の公式ドキュメントには以下の文言があります。
インスタンスを復旧する際、インスタンスを再起動するときにインスタンスは移行され、メモリ内にあるデータは失われます。
ちょっと日本語が不自然な気もするので、英語も見ておきます。
During instance recovery, the instance is migrated during an instance reboot, and any data that is in-memory is lost.
復旧アクション実行時にインスタンスの再起動を伴うことはドキュメントの記載から確実かと思いますので、この記事においては、「AutoRecoveryはライブマイグレーションではない」としています。
ライブマイグレーションでない以上、Auto Recoveryが発生したこと自体がユーザーから見て透過的、ということもないと言えます。(OS止まればさすがに気づくでしょ、という意味で。)
完全に記憶ベースですが、WindowsOSのEC2インスタンスでAuto Recoveryが発生した際には、OSのイベントログに停止したことが記録されていました。EC2インスタンスとして停止→起動であったか、停止を伴わない再起動であったかは失念しましたが、何かしらで痕跡は確認できます。
ちなみに
(引用させていただいた記事ではINSUFFICIENT(データ不足)時に復旧アクションが実行されるようにCloudwatchアラームを設定し、停止することでINSUFFICIENT状態にして挙動を確認していますが、実際には復旧アクションは実施されていないかと想像します。
飽くまでCloudwatchアラームの履歴でアクションが実行されたと表示されただけで、1.で記載した私のパターンと同じように、物理ホストの移動は発生せずに終わったのではないかと考えています。そもそも停止したら、次回起動する際には復旧アクションとは関係なく物理ホストは変動しているはず。。。ただ、2015年の記事なので、その時にはまた事情が違った可能性もあります。)
2.3.CloudWatchでの設定は細かくできるようになった
第一部の※2では「統計で最小を設定することがドキュメントに記載されている」としていますが、2019年現在公式ドキュメントでその記載は確認できません。それは、当時と比べてCloudWatchアラームの閾値まわりの設定を細かくできるようになったためだと考えています。よりユーザーの意図に則した設定が可能となったため、「最小」が必ずしもベストでなくなったということだと理解しています。
2016年当時からCloudWatchまわりで変更が加わった箇所と言えばこちら。
パーセンタイル統計(2016年11月)
Amazon CloudWatch 更新 – パーセンタイル統計およびダッシュボードの新ウィジェット
いまだに使い方が良く分かっていないのですが、突発的に異常値が検出されるようなメトリクスに使うものだと思っています。例えばp95だったら95%、p50だったら50%として、それぞれの%から割り出された「どのくらい通常時とかけ離れたら(これを標準偏差と言ってるのだと思っている)弾く」という基準に則って値を取得する方式のイメージです。AutoRecoveryのトリガーとなる”StatusCheckFailed_System”メトリクスは1か0かなので、あまり関係なかったかもしれません。
Amazon CloudWatch の概念 – パーセンタイル
データ不足時の挙動の定義(2017年3月)
メトリクスの値が欠損したりサンプル数が少なくなった際に、どういった扱いにするかを定義できるようになりました。
CloudWatch Alarms releases two new alarm configuration settings
例えばデータポイントが欠損した場合にそれをどう扱うかとしては、以下の4種があります。
- missing
- そのまま「見つからない」という状態だと判断する。従来はすべてこれに該当した。
- notBreaching
- 「閾値を超えてない」として扱う。
- breaching
- 「閾値を超えた」として扱う。
- ignore
- 「知らない」と言う。直前のアラームのステータスを維持する。
N個中M個のデータポイント(2017年12月)
Amazon CloudWatch アラームで、ある期間に N 個のメトリクスのうち M 個のメトリクスデータポイントがしきい値を上回った場合にアラートが表示される
もはやこれが当たり前すぎて、この仕組みが実装される前の状態が思い出せないのですが、当時は「N個中のN個」、つまり指定した回数分連続で閾値を超えないとアラートにならない、といった仕組みだったかと記憶しています。
アップデートに思いを馳せたところで、次の観点です。
2.4.再起動アクションには必要で復旧アクションには不要なもの
何か分かりますか?
そうですね、サービスリンクロールですね。
再起動アクションどころか、復旧アクション以外のすべてのアクションに必要です。
サービスリンクロールとは、CloudWatchアラームがEC2に対するアクションを実行する際に、その権限の拠り所となるものです。
インスタンスを停止、終了、再起動、または復旧するアラームを作成する
サービスにリンクされたロール AWSServiceRoleForCloudWatchEvents を使用すると、AWS がお客様に代わってアラームアクションを実行できます。AWS マネジメントコンソール、IAM CLI、または IAM API で初めてアラームを作成する場合は、サービスにリンクされたロールが CloudWatch によって作成されます。
IAMユーザーでCloudWatchアラームを作成する際に、併せてサービスリンクロールが作成されるため、そこに対する権限が必要です。お客さんの環境などで、構築用のユーザーに十分な権限が与えられていないとここでエラーが発生しかねないので、注意しましょう。
AWS Identity and Access Management (IAM) ユーザーの場合、アラームを作成または変更するには次のアクセス権限が必要です。
ここでのIAMユーザーは、サービスリンクロールの作成権限だけでなく、CloudWatchアラームの設定に応じた権限が必要になってきます。例えばEC2の停止アクションを行うCloudWatchアラームを作成するなら、EC2の停止権限を持っている必要があります。停止権限が不足している状態でCloudWatchアラームを作成すると、停止アクションが不発に終わることになります。
・iam:CreateServiceLinkedRole、iam:GetPolicy、iam:GetPolicyVersion、および iam:GetRole – Amazon EC2 アクションでのすべてのアラーム用 #1
・ec2:DescribeInstanceStatus と ec2:DescribeInstances – Amazon EC2 インスタンスステータスメトリクスに対するすべてのアラーム用。 #2
・ec2:StopInstances – 停止アクションを含むアラーム用。 #3
・ec2:TerminateInstances – 終了アクションを含むアラーム用。 #4
・復旧アクションを含むアラームに特別なアクセス許可は不要です。 #5
どうしても上記のドキュメントの書き方が許せないのですが、#5の「特別なアクセス許可は不要です」が何にかかるかが分かりますか?
例えばまた停止アクションを例にとると、#1の権限に加え、#3の権限が必要になります。メトリクスとしてインスタンスステータスを設定するなら、#2も追加で必要になります。
#1には「Amazon EC2 アクションでのすべてのアラーム用」と記載があるので、EC2アクションの一つである復旧アクションを作成する時にも当然必要であり、そういった意味で言うと「特別なアクセス許可が不要」と言っているのは、停止アクションにおける#3のようなことを指しているのか、と思いたくなります。
でもそうでないのです。
まず、サービスリンクロールを過去に作成したことがない状態で停止アクションを選択すると、「AWSServiceRoleForCloudWatchEvents」を併せて作るよ、という表示がなされます。
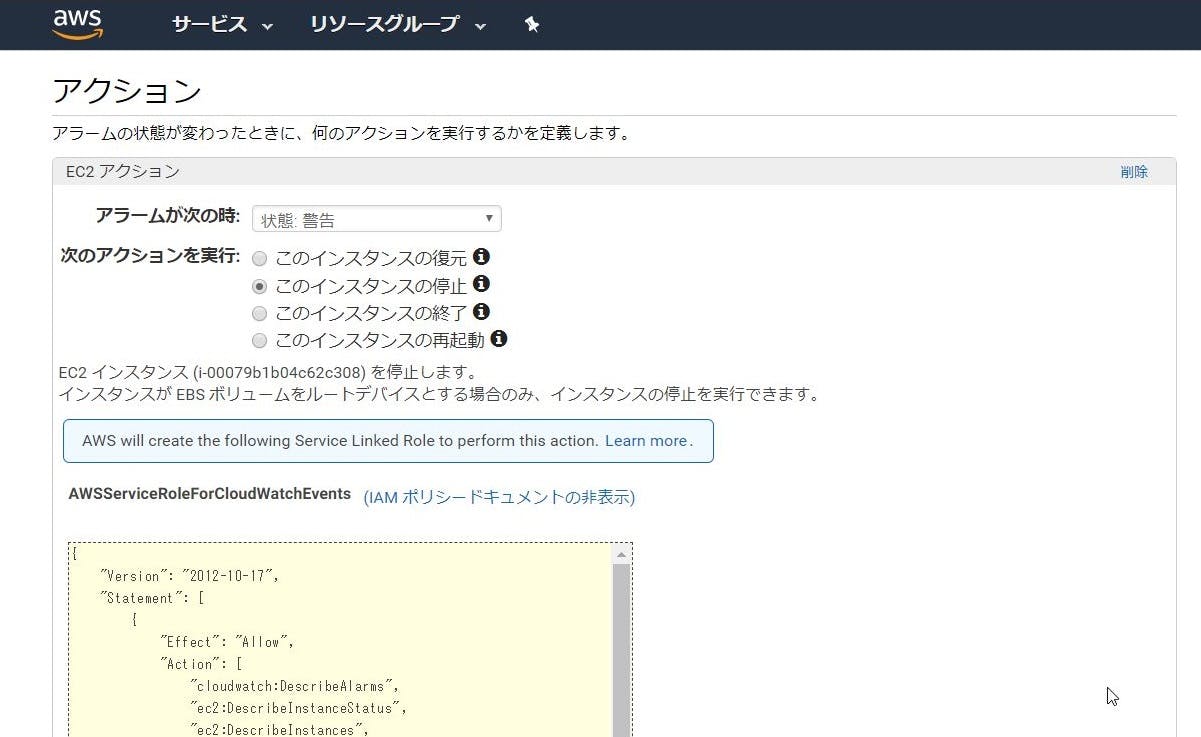
(ちなみにポリシーの内訳はこのような感じ。)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:DescribeAlarms",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribeSnapshots",
"ec2:DescribeVolumeStatus",
"ec2:DescribeVolumes",
"ec2:RebootInstances",
"ec2:StopInstances",
"ec2:TerminateInstances",
"ec2:CreateSnapshot"
],
"Resource": "*"
}
]
}
次に、そのまま復旧アクションを選択すると、何も表示されません。
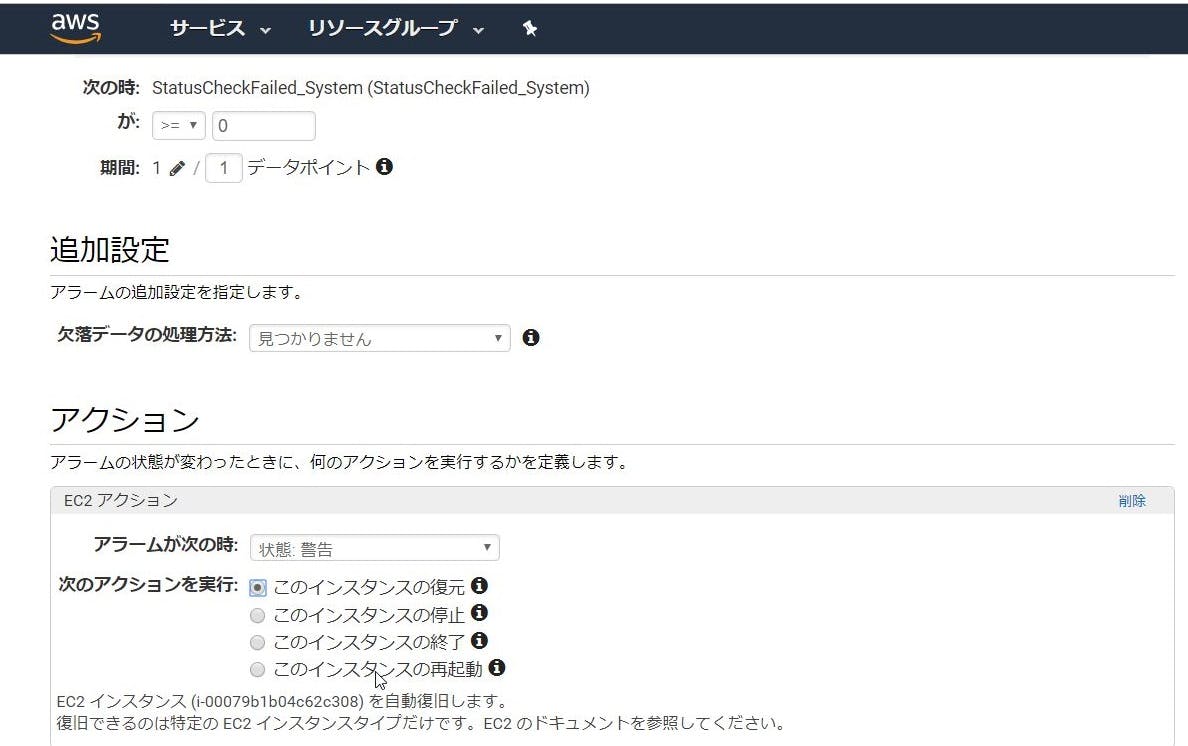
(今さら「復旧」や「復元」の表記ゆれに突っ込むのはやめよう)
つまり、復旧アクションを持ったアラームを作成する際にはサービスリンクロールは作成されず、そういった意味で言うと#1の権限も不要なわけです。そうすると#5の「特別なアクセス許可は不要です」は#1にもかかっており、#1でいう「Amazon EC2 アクションでのすべてのアラーム用」は「ただし復旧アクションは除く」という位置づけになるわけです。
。
。。
でもAWSのドキュメントってそういうものですよね。
アクションの適用対象となる層が違うから?
以下は特に公式でそう表現されているわけではないので、個人の妄想だと捉えてください。
EC2インスタンスを、物理ホスト層があり、EC2インスタンス層があり、その上にOS層がある、という3層構造で考えます。

例えばマネジメントコンソールからEC2インスタンスの停止を選択した場合、それは直接OS層に働きかけているわけではなく、EC2インスタンス層に対するアクションだ、という考え方です。仮想マシンであるEC2インスタンスが停止すれば、そこでホストされているOSも引きずられて停止します。
逆に、OSにログオンして、OS上の操作で停止を行った場合、それに引きずられてEC2インスタンスとしても停止することになります。
CloudWatchアラームによる停止、再起動、終了のアクションは、EC2インスタンス層に働きかけます。直接OS層に働きかけることはありません。EC2インスタンス層に働きかけるためには権限が必要なので、サービスリンクロールによってそこを担保します。
復旧アクションは、物理ホスト上の仮想マシンをマイグレーションするという挙動であり、働きかける対象が物理ホスト層であると捉えています。EC2インスタンス層に働きかけるわけではないので、サービスリンクロールが不要なのだと考えています。
おわりに
というわけで、AutoRecoveryについて思いつくところを調べました。ユーザー側でどうこうできるわけではないので、動作を試したいとなれば、AWSのデータセンターに乗り込んでいってそこら中のケーブルを抜いてくる、くらいしか思いつきません。(得られるものと失うものを天秤にかけると、やらないほうがいいです。)AutoRecoveryが担ってくれる領域とそうでない領域をきちんと理解し、障害時を踏まえた適切な設計をしましょう。
こちらからは以上です。
![pipで[SSL: CERTIFICATE_VERIFY_FAILED]が出る場合の解決法](https://www.simpline.co.jp/wp-content/themes/sankakuya_skelton/img/noimage.png)